
정말 오랜만에 코딩 테스트를 위해 파이썬을 켜봤다.
코테를 준비할 때 많이 사용했었던, 또 헷갈려서 매일 검색하던것을 이 곳에 정리한다.
후에, 코테 능력이 매우 향상되었을 때 이미 체득한 것을 지워서 궁극적으로는 이 문서가 없어지길 바라면서..
[ 반복문 - for문 ]
- break는 어떤 if 조건에서 만족했다면, 이제 반복문에서 나오자!
for i in example:
if i=="i":
break
# for문에서 나오게 된 뒷 코드부터 실행하게 된다.- continue는 여러 if 들이 있을 때, 초반의 if 에서 만족하게 되어서 뒷 if를 돌지 않아도 될 때!
for s in examples:
if s=="a"
# 코드 실행
continue
if s=="b"
# 코드 실행
continue
if s=="c"만약 s가 b라는 조건을 만족하면 뒤의 if문은 돌지 않아도 되므로, if를 빠져나오기 위해 continue 사용
[ enumerate ]
enumerate : 열거하다, 나열하다
for문 사용 시, index와 value를 함께 알고 싶을 때 주로 사용하면 좋다.
arr=[1,2,3,4]
for i, v in enumerate(arr):
print(i, v)
# 결과값 : 0,1
1,2
2,3
3,4[ 한 문장 주석, 전체 문장 주석 : 단축키 ]
한 문장 주석 : #
전체 문장 주석 : Command + / (Ctrl + /)
[ 파이썬에서의 참/거짓(Boolean) 판별 ]
bool() 함수 사용
EX] bool(5) # True
bool(0) # False
조건문에서 True, False 판별
if a==True
[ 논리곱 수행 연산자 ]
and or
[ 리스트 내의 원소 삭제하기]
1. clear()
리스트 전체 원소 삭제
EX] a.clear()
2. pop()
특정 인덱스의 값을 삭제
a.pop(1) # 1번 인덱스의 값을 없앤다
a.pop() # a 리스트의 마지막 값을 삭제한다.
3. remove()
특정 값의 원소를 없앤다.
만약, 같은 원소가 여러개 있으면 가장 앞에 있는것 하나만 삭제한다.
a.remove("hi")
4. del
지우고 싶은 값을 없앤다.
del a[1] #a[1]의 값을 없앤다.
[ 리스트의 값을 비교해보자! ]
먼저, 교집합, 합집합, 차집합을 만들기 전에 리스트를 set으로 만든다.
EX] set([1,2,3,4,])
1. 교집합
print(set1 & set2)
print(set1.intersection(set2))2. 합집합
print(set1 | set2)
print(set1.union(set2))3. 차집합
print(set1 - set2)
print(set1.difference(set2))4. 리스트 비교
1) 정렬 후 비교
sorted(list1) == sorted(list2)2) set으로 정렬 후 비교
set(list1) == set(list2)3) numpy 사용
import numpy as np
arr1 = np.array([[1, 2], [3, 4]])
arr2 = np.array([[1, 2], [3, 4]])
print(np.array_equal(arr1, arr2))
# True
np.equal(a, b)
# [False True False]파이썬 리스트 비교 (같은값, 다른값) [set자료형(합집합,교집합,차집합), numpy]
파이썬에서 set은 집합을 뜻한다.크기순으로 정렬한 list의 길이가 같고 요소들이 같을 경우 True를, 그렇지 않은 경우 False를 반환각각의 요소를 비교
velog.io
[ 리스트 내 중복 개수 계산 ]
1. count()
lis.count(1)
2. 중복 요소 삭제
arr=set(lis) # 먼저 set으로 바꾸고
arr=list(arr) # 다시 list로 바꿔준다.
[ 문자열을 대/소문자로 바꾸기, 숫자 판별 ]
1. 문자열을 대문자로 변환
s2 = s1.upper()2. 문자열을 소문자로 변환
s2 = s1.lower()3. 문자열이 대문자인가?
if s1.isupper(): # 모든 문자가 대문자였나?
# 실행 코드4. 문자열이 소문자인가?
if s1.islower(): # 모든 문자가 대문자였나?
# 실행 코드5. 숫자인가?
s1.isdigit()6. 알파벳인가?
s1.isalpha()7. 숫자와 알파벳으로만 구성되어 있는가?
공백이 있으면 False 반환
s1.isalnum()[ 아스키 코드로 변환하기 ]
ord("문자")
chr(숫자)
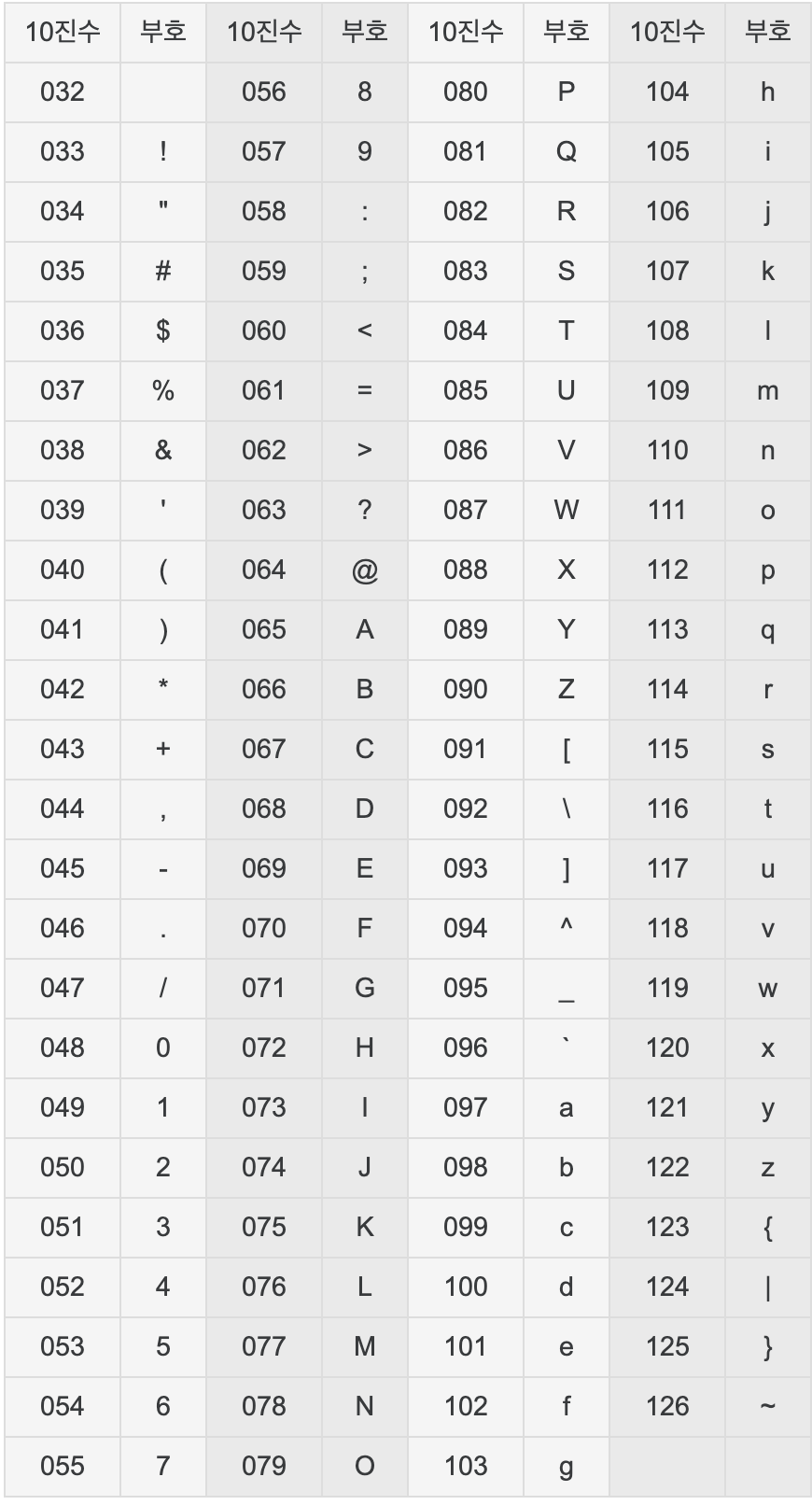
출처 : 나무위키
[ 문자열에서 문자 삭제하기 ]
1. strip
list1.strip(삭제할 문자, 문자열)
- 만약, 앞 뒤에 공백과 같은 것이 있다면,
list1.strip()사용하게 되면 앞 뒤에 공백이 없어진다.
- 여러개의 문자를 삭제하고 싶다면,
list1.strip("a")문자열 내 모든 a가 없어진다.
2. replace
list1.replace("a", "b")
# "a"라는 문자들을 모두 "b"로 바꾼다!3. re.sub()
import re
words = "password486"
new_words = re.sub(r"[a-z]", "", words)
print(new_words) # 486출처 : https://engineer-mole.tistory.com/238
[python] 문자열에서 특정(일부) 문자만 삭제하는 방법들
이번 포스팅에서는 python에서 불필요한 물자열을 삭제하는 네 가지 방법에 대해 알아보고자 한다. - strip 메소드 : 양 끝의 불필요한 문자를 삭제한다. - replace 메소드 : 지정 문자열을 치환하여
engineer-mole.tistory.com
[ 반올림, 올림, 내림 ]
import math를 넣어서 반올림, 올림, 내림을 할 준비를 한다
1. 반올림
round()
2. 올림
math.ceil()
3. 내림
math.()
[ Heap ]
리스트를 바로 정렬할 수 있고, 최솟값을 찾는 속도가 빠르다.
정확도 문제일 시, 이 heap을 사용한다.
예] 프로그래머스 더 맵게
from heapq import heapify, heappush, heappop
def solution(scoville, k):
count=0 # 섞은 횟수
heapify(scoville)
while scoville[0]<k:
try:
heappush(scoville, heappop(scoville)+(heappop(scoville)*2))
count+=1
except IndexError:
return -1
return count- heapify() : 리스트를 힙으로 만들어 준다
- heappush() : 힙에 원소를 넣는다
- heappop() : 힙에서 최솟값, 맨 처음 있는 원소를 빼낸다.
[ while 문을 사용할 때 ]
위의 더 맵게 문제 처럼
while scoville[0]<k:
try:
# 실행할 코드
except IndexError:
return -1구조를 사용하도록 하자...
[ BFS, DFS 기본 구조 ]
from collections import deque
answer=0
directions=[(0,1), (0,-1), (-1, 0), (1,0)]
for sy in range(n):
for sx in range(m):
if image[sy][sx]==float('inf'):
continue
target_color=image[sy][sx]
queue=deque([sy, sx])
while queue:
y, x= queue.popleft()
for dy, dx in directions:
py=y+dy
px=x+dx
if px>=m or px<0 or py>=n or py<0:
continue
if image[py][px] == target_color:
image[py][px] = float('inf')
queue.append((py, px))
answer += 1
directions = [(0, 1), (0, -1), (-1, 0), (1, 0)]
[ 파이썬 내림차순 정렬 ]
list.sort(reverse=True)
[ 리스트 내의 중복 제거 ]
set 자료형 사용!
list_to_set = set(list1) # set 자료형으로 변환
list1 = list(list_to_set) #list로 변환
[ 딕셔너리에서의 정렬 ]
sorted(answer, key=lambda x:answer[x], reverse=True)딕셔너리에서 value값을 기준으로 정렬하되, 내림차순으로 정렬하고자 할 때 사용한다.
[ 람다(lambda) ]
def key_result(x):
a=answer[x]
return a
# lambda x:answer[x][ 특수 문자 제거 ]
paragraph = re.sub('[-=+,#/\?:^.@*\"※~ㆍ!』‘|\(\)\[\]`\'…》\”\“\’·]', ' ', paragraph)
paragraph=paragraph.lower().split(" ")[ 2차원 리스트 내의 최대값 찾기 ]
max_val = max(map(max, data))[ 순열 조합 라이브러리 사용법]
# 순열 조합 라이브러리 사용
from itertools import combinations
for choose in combinations(cards, 3):
tmp_sum=sum(choose)
if answer<tmp_sum<=m:
answer=tmp_sum
'Today I Learned > 코딩테스트 준비' 카테고리의 다른 글
| SQL JOIN 시 포맷 (0) | 2022.11.01 |
|---|---|
| 파이썬에서 is와 ==의 차이점 (0) | 2022.06.03 |
| [Python] sort() vs sorted (0) | 2020.12.23 |